
티스토리 뷰
스프링 입문 - 코드로 배우는 스프링 부트, 웹 MVC, DB 접근 기술 - 김영한 인프런 강의 참고
Goals
- JPA를 사용하지 않았을 때의 불편함
- JPA란?
- JPA를 사용하는 이유
JPA를 사용하지 않았을 때의 불편함
우리가 JDBC API를 사용하는 이유는 자바 애플리케이션이 관계형 데이터베이스(보통의 경우)로 데이터를 관리하기 위해 SQL을 전달해야 하기 때문이다. 그래서 개발자는 당연히 SQL문을 JDBC API의 도움을 받아 다루게 되고 이 과정에서 문제가 발생한다.
반복적인 로직
이전의 예제에서도 언급했는데, JDBC API를 사용했을 때 가장 쉽게 발견할 수 있었던 문제점이다.
// ...
@Override
public Member save(Member member) {
String sql = "insert into member(name) values(?)";
// DB의 연결 정보를 가지고 일정 시간 동안 DB와 연결할 수 있도록 통로 역할을 하는 객체
Connection conn = null;
// 다양한 SQL 구문들을 정의하고 바인딩 하는 방법들과 실제 DB로 전송하는 방법들이 정의된 객체
PreparedStatement pstmt = null;
// sql 쿼리 결과를 저장하는 데이터 집합 객체
ResultSet rs = null;
try {
conn = getConnction();
pstmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
// ...
} catch (Exception e) {
throw new IllegalStateException(e);
} finally {
// 할당한 리소스 해제
close(conn, pstmt, rs);
}
}
// ...
위의 코드가 DB에 한 번 접근할 때마다 지속적으로 반복해야 할 로직이다.
특히 기본적인 CRUD 로직들은 수 없이 반복될 것이고, 비슷비슷한 SQL문 및 JDBC API 코드들을 개발자들이 일일이 반복 작성해야 하는 지루한 작업이다.
이러한 반복 작업이 필요한 근본적인 이유는 객체 지향 애플리케이션과 데이터 중심의 DB 사이에서 JDBC API를 사용해서 변환 작업을 해줘야 하기 때문이다.
SQL에 의존적인 개발
만약 아래의 Member 테이블에서 address라는 필드를 하나 추가한다고 가정해 보자.
// ...
public class Member {
private Long id;
private String name;
private String address; // 추가
// ...
}그럼 개발자는 위의 save 메서드에서 address도 함께 저장하도록 수정해야 하며, 회원 정보 표시 시 address도 추가되어야 하므로 조회 메서드 및 수정 메서드 역시 수정해야 한다. 그런데 이 수정 작업 시 당연하게도 작성된 SQL을 직접 확인하고 수정해야 한다.
또한 데이터 접근 메서드에 오류가 발생했을 시, 자바 코드를 확인하는 것뿐만 아니라 SQL문이 잘못됐을 가능성을 확인해야 한다. 이를 요약하면 아래와 같다.
- 진정한 의미의 계층 분할이 어렵다.
- 엔티티를 신뢰할 수 없다.
- SQL에 의존적인 개발을 피하기 어렵다.
패러다임의 불일치
객체 지향 애플리케이션은 추상화, 캡슐화, 상속, 다형성 등의 방식을 이용해서 객체와 객체 간의 관계들을 정의하고 관리한다. 하지만 관계형 데이터베이스는 추상화, 캡슐화 같은 개념이 없으며, 데이터 중심으로 구조화되어 있고, 집합적인 사고를 요구한다.
결국 서로 지향하는 목적이 다르므로 기능과 표현 방법도 달라진다. 이러한 패러다임 불일치 문제 때문에 객체 구조를 테이블 구조에 저장하는 데는 한계가 있다.
어쩔 수 없이 개발자가 위 문제를 중간에서 해결해야 했고, 이는 너무 많은 시간과 코드를 소비하게 되어 문제가 발생한다.
- 연관관계
- 객체 그래프 탐색
- 비교
예를 들어 위 Member 클래스와 연관관계를 맺는 Team 클래스가 있다고 해보겠다.
class Member {
private Long id;
private String name;
private Team team; // Team 클래스와 연관관계
Team getTeam() {
return team;
}
}
class Team {
private Long id;
private String name;
// ...
}객체는 참조를 사용해서 다른 객체와 연관관계를 가지는 반면, 테이블은 외래 키를 사용해서 다른 테이블과 연관관계를 가진다.

때문에 객체를 테이블에 저장하거나 조회하기가 쉽지 않아진다. 객체 모델은 참조만 있고 외래 키는 없으며, 테이블은 외래 키만 있고 참조는 없기 때문이다. 결국, 개발자가 참조와 외래 키를 중간에서 변환해 줘야 한다.
Member 객체를 저장하기 위해서 member.getTeam().getId()를 호출해 테이블의 FK인 team_id 속성에 저장해 줘야 한다.
조회는 더 귀찮아진다. Member 객체를 얻기 위해서는, 테이블에서 조회한 결과 값들에서 member 테이블의 team_id 속성을 Member 객체가 참조하고 있는 Team 객체로 변환해줘야 한다.
public Member find(Long memberId) {
// SQL 실행
// ...
Member member = new Member();
Team team = new Team();
// 데이터베이스에서 조회한 member 및 team 관련 정보를 객체에 저장
// ...
// 연관관계 설정
member.setTeam(team);
return member;
}만약 데이터베이스가 객체 지향이었으면 조회한 테이블 결과를 단순히 Member에 담기만 했으면 끝났을 텐데, 각 객체를 따로따로 담아서 연관관계까지 또 설정해 줘야 한다.
더 큰 문제는 객체 그래프 탐색 시에 발생한다. 만약 객체 연관관계가 다음과 같이 설계되어 있다고 가정해 보자.
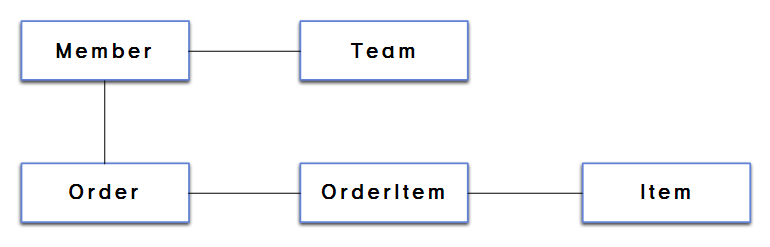
객체는 본래 연관관계를 맺은 객체들과 마음껏 객체 그래프 탐색을 할 수 있다. 하지만 데이터베이스에 있는 데이터를 가져온 경우라면 그렇지 않다.
Member member = mrmberDAO.find(memberId);
member.Team()
member.getOrder().getOrderItem()
member.getOrder().getOrderItem().Item()만약 find 메서드가 member 테이블의 데이터만 조회했다면 위 코드의 결과 값에는 모두 null이 반환될 것이다. 만약 team 테이블과 join을 했다면 member.Team()은 Team 객체를 얻을 수 있겠지만 그 외 코드에서는 역시 null이다.
이는 SQL을 직접 다루면 처음 실행하는 SQL에 따라 객체 그래프를 어디까지 탐색할 수 있는지 정해지기 때문이다. 결국 아래와 같이 여러 개의 조회 메서드를 구현해야 한다.
memberDAO.find()
memberDAO.findWithTeam()
memberDAO.findWithOrderWithOrderItem()
...
이는 실제 일어날 수 있는 매우 흔한 예이다. 필자도 프로젝트 시 여러 개의 조회 메서드를 구현해야 하는 상황이 빈번했다.
마지막으로 비교 상황에서의 문제점이다. 데이터베이스는 기본 키의 값으로 각 row를 구분한다. 반면에 객체는 동일성 비교와 동등성 비교라는 두 가지 비교 방법이 있다.
- 동일성(identity) 비교 :
==,객체 인스턴스의 주소 값을 비교 - 동등성(equality) 비교 :
equals()메소드를 사용해서 객체 내부의 값을 비교
위의 문제점은 이전 포스팅에서 다뤘던 테스트 시 발생했었다.
@Test
public void 회원가입() throws Exception {
// Given
Member member = new Member();
member.setName("hello");
// When
Long saveId = memberService.join(member);
// Then
Assertions.assertThat(memberRepository.findById(saveId).get()).isEqualTo(member); // 테스트 실패
Member findMember = memberRepository.findById(saveId).get();
assertEquals(member.getName(), findMember.getName());
}위 테스트는 Member 객체를 생성해 DB에 저장한 뒤, PK인 id로 다시 조회해 올바르게 저장됐는지 비교하는 테스트다.
Assertions.assertThat(memberRepository.findById(saveId).get()).isEqualTo(member);
위 코드로 테스트를 하게 되면 두 객체의 주소 값을 비교하게 된다. 따라서 위 메서드에서 생성한 member 객체와 같은 id 값을 가진 데이터를 조회해 비교를 하더라도, 조회 시 객체를 새로 생성하기 때문에 주소 값이 달라 실패한다.
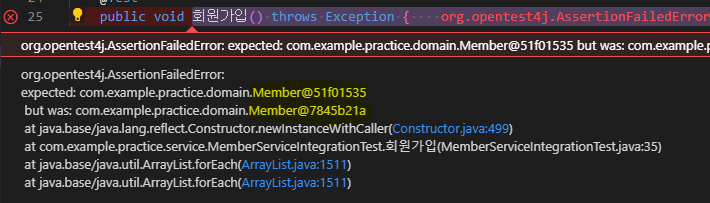
대신에 name 속성을 비교하는 동등성 비교를 선택할 수밖에 없었다.
하지만 데이터 상으로는 사실 id 값이 같은, 동일한 row의 데이터이므로 같아야 한다.
위와 같은 문제들을 JPA는 아주 합리적이고 효율적으로 해결해 주기 때문에 현재 자바 진영에서 ORM 기술 표준이 된 것이다.
JPA(Java Persistence API)란?
JPA는 자바 진영의 ORM 기술 표준으로 애플리케이션과 JDBC 사이에서 동작한다.
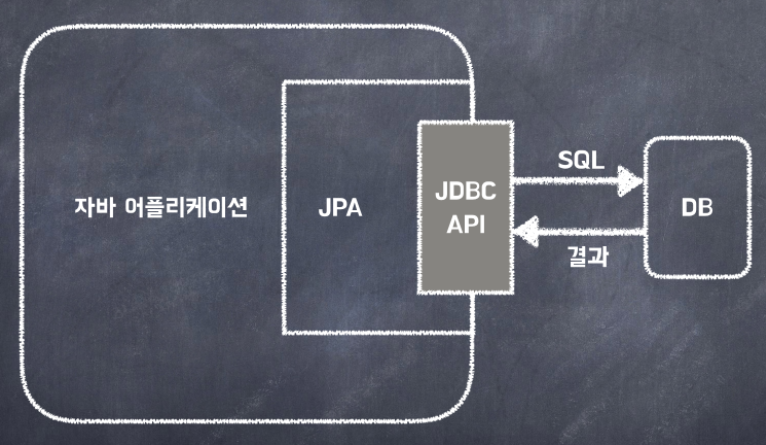
여기서 ORM(Object-Relational Mapping)이란 이름 그대로 객체와 관계형 데이터베이스를 매핑한다는 뜻이다. 위에서 설명했던 객체와 테이블 간의 패러다임 불일치 문제를 개발자 대신 해결해 준다.
예를 들어 JPA를 사용해서 조회하는 코드는 다음과 같다.
Member member = jpa.find(memberId);
이전처럼 SQL을 직접 작성하거나 조회한 데이터를 일일이 객체의 속성 값에 맞게 담지 않고 바로 객체를 직접 조회할 수 있다.
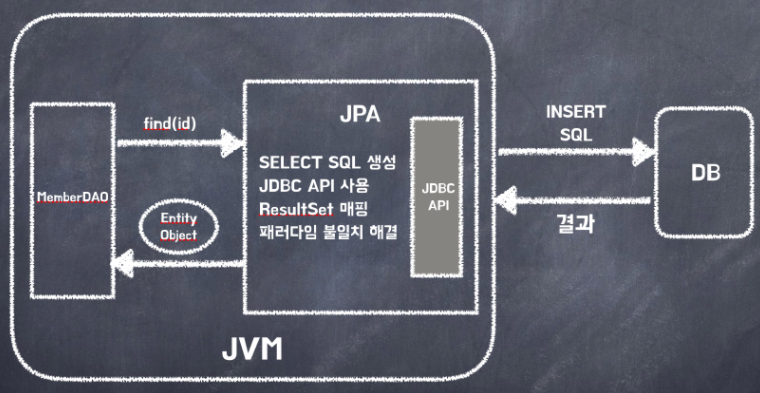
개발자는 그저 객체와 데이터베이스 테이블을 어떻게 매핑해야 하는지 매핑 방법만 ORM 프레임워크에게 알려주면 된다.
오해하지 말아야 하는 게, JPA는 자바 ORM 기술에 대한 API 표준 명세로 인터페이스일 뿐이다. 우리가 사용하는 것은 이를 구현한 ORM 프레임워크 구현체다. 가장 대중적으로 사용하는 프레임워크는 오픈소스인 Hibernate가 있다.
MORE THAN AN ORM, DISCOVER THE HIBERNATE GALAXY. -https://hibernate.org/
JPA를 사용하는 이유
생산성
JPA를 사용하면 자바 컬렉션에 객체를 저장하듯이 JPA에게 저장할 객체를 전달하면 된다.
jpa.persist(member); // 저장
지루하고 반복적인 코드와 CRUD용 SQL을 개발자가 직접 작성하지 않아도 된다. 또한 CREATE TABLE 같은 DDL 문을 자동으로 생성해 주는 기능도 있다. 이로 인해 데이터베이스 설계 중심 패러다임을 객체 설계 중심으로 역전시킬 수 있다.
유지보수
SQL을 직접 다루면 엔티티에 필드를 하나만 추가해도 관련된 여러 로직들을 다 수정해야 하는 예시를 위에서 들었다. 하지만 JPA는 이를 대신 처리해 주므로 유지보수 부담이 크게 줄어 든다. 즉, 개발자가 작성해야 했던 SQL과 JDBC API 코드를 JPA가 대신 처리해주므로 유지보수해야 하는 코드 수가 확연하게 줄었다.
패러다임 불일치 해결
패러다임 불일치 문제는 근본적인 문제로 다양한 문제들을 계속해서 파생시킨다. JPA는 연관관계, 객체 그래프 탐색, 비교하기와 같은 패러다임의 불일치 문제를 합리적으로 해결해 준다.
데이터 접근 추상화와 벤더 독립성
관계형 데이터베이스는 같은 기능도 벤더마다 사용법이 다른 경우가 많다. 예로 페이징 처리가 있는데, SQL문을 직접 다루게 되면 애플리케이션은 선택한 데이터베이스 기술에 종속되게 된다. 하지만 JPA는 데이터베이스를 변경할 때 다른 데이터베이스를 사용한다고 알려주기만 하면 된다.
표준
JPA는 자바 진영의 ORM 기술 표준이므로 다른 구현 기술로 손쉽게 변경할 수 있다.
다음 포스팅에서는 Spring Boot 프로젝트에 JPA를 적용해 보겠다.
Reference
'Spring&Spring Boot' 카테고리의 다른 글
| [Spring Boot] 입문 - Spring Data JPA 맛보기 (0) | 2023.02.25 |
|---|---|
| [Spring Boot] 입문 - Spring Boot 프로젝트에 JPA 적용하기 (0) | 2023.02.24 |
| [Spring Boot] 입문 - JDBC Template(feat. 스프링 통합 테스트) (0) | 2023.02.21 |
| [Spring Boot] 입문 - 순수 JDBC로 DB 연결하기(feat. mysql) - 2 (1) | 2023.02.17 |
| [Spring Boot] 입문 - 순수 JDBC로 DB 연결하기(feat. mysql) - 1 (0) | 2023.02.17 |
- Total
- Today
- Yesterday
- 선형 회귀
- 스프링
- Spring Data JPA
- 스프링 테스트
- 쉘 코드
- jsp
- 스프링 컨테이너
- Python Cookbook
- Spring
- 파이썬 for Beginner 연습문제
- 방명록 프로젝트
- Gradle
- 운영체제 반효경
- 지옥에서 온 git
- 생활코딩 javascript
- git
- 스프링 mvc
- JPA
- Spring Boot
- 프로그래머스
- Computer_Networking_A_Top-Down_Approach
- git merge
- fetch join
- git branch
- 패킷 스위칭
- 김영환
- 쉽게 배우는 운영체제
- Thymeleaf
- Do it! 정직하게 코딩하며 배우는 딥러닝 입문
- 파이썬 for Beginner 솔루션
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |