
티스토리 뷰
Git 개요
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency. - https://git-scm.com/
Git은 분산형 버전 관리 시스템(Version Control System, VCS)으로, 소스 코드의 변경 내역을 추적하고 여러 개발자가 협업할 수 있도록 돕는 도구다. 현대 개발자들에게 Git 없이 개발하라고 하는 것은 목숨이 1개 밖에 없는 게임을 플레이 하는 것처럼 살얼음판을 걷는 기분일 것이다. 특히나 “협업”을 할 때, GIt은 선택이 아닌 “필수”다.
Git 이전에도 SVN(Subversion)이나 CVS(Concurrent Versions System)같은 버전 관리 시스템은 있었다. 하지만 이게 마음에 들지 않았던 리누스 토르발스(Linus Benedict Torvalds)가 Linux 커널 개발을 할 때 편하게 사용하려고 2주만에 만들었다. 초기 목표는 다음과 같았다.
- 빠른 속도
- 단순한 구조
- 비선형적인 개발(수천 개의 동시 다발적인 브랜치)
- 완벽한 분산
- Linux 커널 같은 대형 프로젝트에도 유용할 것(속도나 데이터 크기 면에서)
그런 GIt이 2024년 10월 기준으로 75,117개의 commit이 달린 프로젝트로 구글, 마이크로소프트 등의 거대 소프트웨어 기업들도 사용하는 툴이 됐고, IDLE에서는 사용자가 프로젝트를 생성할 때부터 Git으로 버전 관리를 할 수 있게 해뒀다. 또한 Git 저장소를 원격으로 호스팅하는 플랫폼인 Github는 자유 소프트웨어와 오픈 소스 진영의 성지가 됐다.

어쨌든, 개발자 입장에서 Git은 옆에서 우리를 도와주는 동반자 역할을 할 것이다. 이런 Git을 시작하는 방법은 너무 간단하다. 배우기도 쉽다. 하지만 모든 도구가 그렇듯, “잘” 사용하는 것과는 다르다. 단순히 명령어를 외우고 따라 치다 보면 금방 까먹는다. commit과 branch가 꼬여서 왜 이렇게 됐는지 이해되지 않아 결국 강제 reset을 하거나, 작업하던 것을 새로운 곳에 옮긴 후 다시 pull을 반복한 경험이 있을 것이다.
Git의 핵심은 뭘까? 이 질문은 Git을 이해하는데 굉장히 중요하다. Git이 무엇이고 어떻게 동작하는지 이해하려고 조금만 노력하면 Git을 더 깊게 이해하는 기반을 다질 수 있고, 더 나아가 명령어들을 사용하는데 있어 두려움도 줄어들 것이다. 본 포스팅만으로 Git을 전부 이해하는데는 분명 무리가 있겠지만, Git이 그저 검은 터미널 화면 속 미지의 존재가 아니라, 더 알아가고 싶은 동반자가 되길 바라는 마음이다.
Git의 핵심 요약
차이(Delta)가 아니라 스냅샷(Snapshot)
이전의 VCS들과 Git의 가장 큰 차이점은 데이터를 다루는 방법에 있다. 큰 틀에서 봤을 때 VCS 대부분은 관리하는 정보가 파일들의 목록이다. 각 파일의 변화를 시간순으로 관리하면서 파일들의 집합을 관리(Delta-based VCS)한다.
위 그림을 예로 들면, Version 2에서는 Fila A의 변경점과 File C의 변경점만을 저장한다. 다음 Version 3에서는 File C의 변경점만 저장한다. 이런 식으로 이전 버전과의 차이점(델타)만 저장하는 방식이다. 이 방식의 문제점은 해당 파일의 최종 상태를 만들기 위해 여러 델타를 조합해야 한다는 것이다.
만약에 File C의 최신 상태를 알고 싶다고 해보자.
- Version 5의 수정 사항 → Version 3의 수정사항 → Version 2의 수정사항
이런 식으로 특정 파일의 최신 상태를 알기 위해 역추적을 하며 여러 델타를 조합해야 하며, 이는 프로젝트의 규모가 클수록 큰 부담이 된다.
대신 Git은 데이터를 파일 시스템 스냅샷의 연속으로 취급하고 크기가 아주 작다. Git은 커밋하거나 프로젝트의 상태를 저장할 때마다 파일이 존재하는 그 순간을 중요하게 여긴다. 파일이 달라지지 않았으면 Git은 성능을 위해서 파일을 새로 저장하지 않는다. 단지 이전 상태의 파일에 대한 링크만 저장한다. Git은 데이터를 스냅샷의 스트림처럼 취급한다.
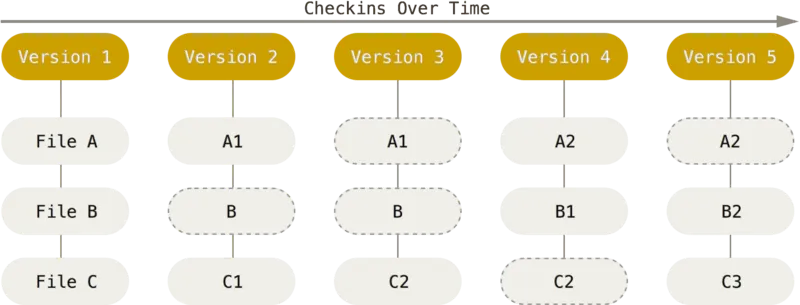
만약 최신 상태의 File C가 궁금하다면, 그저 Version 5의 File 5를 조회하면 된다. 즉, 가장 최신의 버전이 현재 프로젝트의 최신 상태인 것이다. 또한 변경사항이 없는 File A는 Version 5에 직접 저장되지 않고 Version 4의 스냅샷 링크만을 가지고 있다. Git이 가진 이 간단한 원칙이 다른 VCS와 크게 구분되는 점이다. 이점 때문에 Git은 다른 시스템들이 과거로부터 답습해왔던 버전 컨트롤의 개념과 다르고 추후 브랜치(branch)라는 기능이 추가될 때 엄청난 이점을 가져온다.
거의 모든 명령을 로컬에서 실행
거의 모든 명령이 로컬 파일과 데이터만 사용하기 때문에 네트워크에 있는 다른 컴퓨터는 필요 없다. Git만 사용해온 사람들은 이게 뭐 그리 대단한 것이냐고 하겠지만, 이전의 VCS에서는 그렇지 않았다. 이전의 버전 정보를 가져오려면 서버에 연결해야 하는 VSC들도 많았기 때문에 단순히 명령어를 입력할 때도 네트워크의 속도에 영향을 받아야 했다. 반면 Git은 프로젝트의 모든 히스토리가 로컬 디스크에 있기 때문에 모든 명령이 순식간에 실행된다.
예를 들어 Git은 프로젝트의 히스토리를 조회할 때 서버 없이 조회한다. 그냥 로컬 데이터베이스에서 히스토리를 읽어서 보여 준다. 그래서 눈 깜짝할 사이에 히스토리를 조회할 수 있다. 어떤 파일의 현재 버전과 한 달 전의 상태를 비교해보고 싶을 때도 Git은 그냥 한 달 전의 파일과 지금의 파일을 로컬에서 찾는다. 파일을 비교하기 위해 리모트에 있는 서버에 접근하고 나서 예전 버전을 가져올 필요가 없다. 행기나 기차 등에서 작업하고 네트워크에 접속하고 있지 않아도 커밋할 수 있다.
Git의 무결성
Git은 데이터를 저장하기 전에 항상 체크섬을 구하고 그 체크섬으로 데이터를 관리한다. 그래서 체크섬을 이해하는 Git 없이는 어떠한 파일이나 디렉토리도 변경할 수 없다. 체크섬은 Git에서 사용하는 가장 기본적인(Atomic) 데이터 단위이자 Git의 기본 철학이다. Git 없이는 체크섬을 다룰 수 없어서 파일의 상태도 알 수 없고 심지어 데이터를 잃어버릴 수도 없다.
Git은 SHA-1 해시를 사용하여 체크섬을 만든다. 만든 체크섬은 40자 길이의 16진수 문자열이다. 파일의 내용이나 디렉토리 구조를 이용하여 체크섬을 구한다. SHA-1은 아래처럼 생겼다.
24b9da6552252987aa493b52f8696cd6d3b00373
Git은 모든 것을 해시로 식별하기 때문에 이런 값은 여기저기서 보인다. 실제로 Git은 파일을 이름으로 저장하지 않고 해당 파일의 해시로 저장한다.
Git은 데이터를 추가할 뿐 삭제하지 않는다
Git으로 무얼 하든 Git 데이터베이스에 데이터가 추가된다. 되돌리거나 데이터를 삭제할 방법이 없다. 다른 VCS처럼 Git도 커밋하지 않으면 변경사항을 잃어버릴 수 있다. 하지만, 일단 스냅샷을 커밋하고 나면 데이터를 잃어버리기 어렵다.
Git이 관리하는 파일의 3가지 상태
Git을 공부하기 위해 반드시 짚고 넘어가야 할 부분이다. Git은 파일을 Committed, Modified, Staged 이렇게 세 가지 상태로 관리한다.
- Committed란 데이터가 로컬 데이터베이스에 안전하게 저장됐다는 것을 의미한다.
- Modified는 수정한 파일을 아직 로컬 데이터베이스에 커밋(commit)하지 않은 것을 말한다.
- Staged란 현재 수정한 파일을 곧 커밋할 것이라고 표시한 상태를 의미한다.
이 세 가지 상태는 Git 프로젝트의 세 가지 단계와 연결돼 있다.
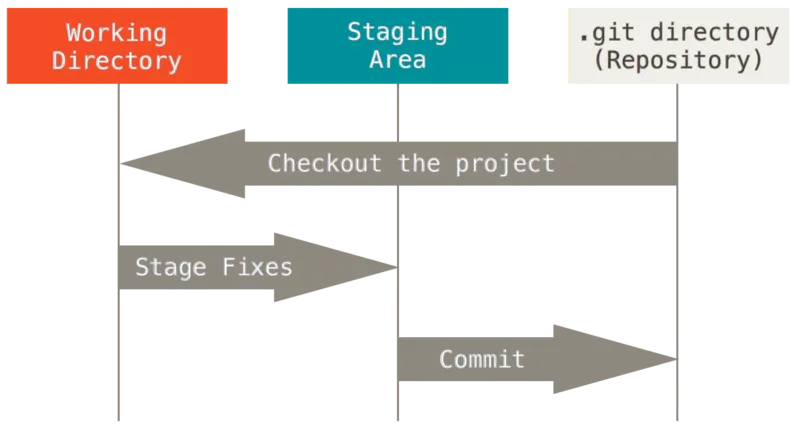
Git 디렉토리는 Git이 프로젝트의 메타데이터와 객체 데이터베이스를 저장하는 곳을 말한다. 이 Git 디렉토리가 Git의 핵심이다. 다른 컴퓨터에 있는 저장소를 Clone하거나 Git을 시작하는 init 명령어를 수행할 때 Git 디렉토리가 만들어진다.
워킹 트리(Working Directory or Tree)는 프로젝트의 특정 버전을 Checkout 한 것이다. Git 디렉토리는 지금 작업하는 디스크에 있고 그 디렉토리 안에 압축된 데이터베이스에서 파일을 가져와 워킹 트리를 만든다.
Staging Area는 Git 디렉토리에 있다. 단순한 파일이고, 곧 커밋할 파일에 대한 정보를 저장한다. 쉽게 말해 Git에서 버전 관리하고 싶은 파일을 Staging Area에 등록하면 된다. Git에서는 기술용어로 “Index” 라고 하지만, “Staging Area” 라는 용어를 써도 상관 없다.
위 3가지 단계를 기반해서, Git으로 하는 일은 보통 아래와 같다.
- 워킹 트리에서 파일을 생성 및 수정한다.
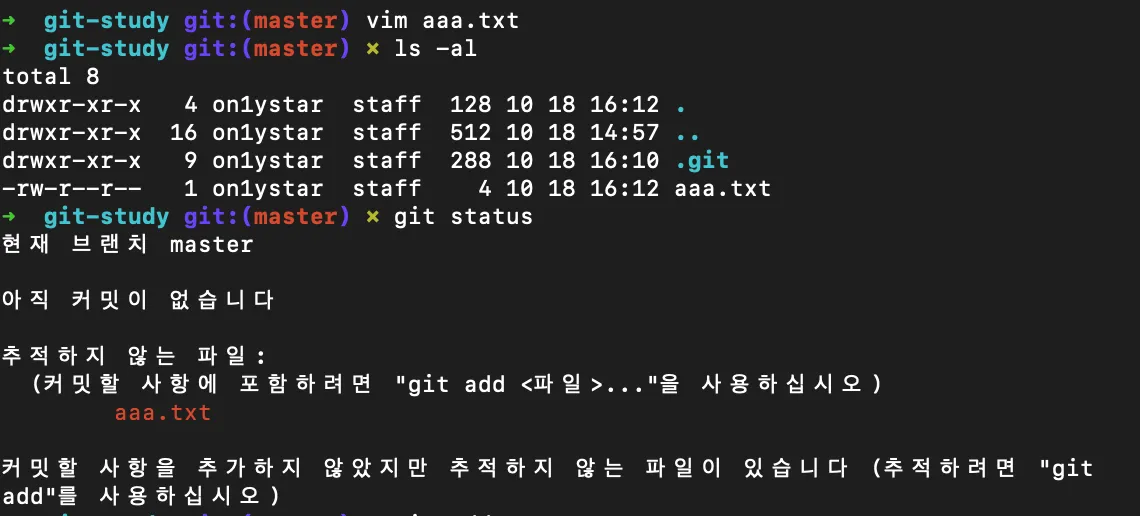
위 그림에서 aaa.txt 파일을 하나 생성했다. aaa.txt는 아직 Staging Area에 등록한 Staged 파일이 아니기 때문에 Git에서 버전 관리하고 있지 않은 파일이다.
- Staging Area에 파일을 Stage 해서 커밋할 스냅샷을 만든다. 모든 파일을 추가할 수도 있고 선택하여 추가할 수도 있다.
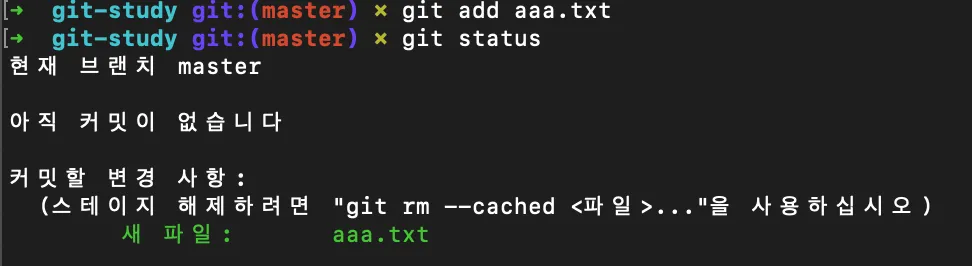
add 명령어로 aaa.txt 파일을 Staging Area에 등록했다. 이제 이 파일의 변경사항은 Git에 의해 추적되고, 커밋 대기 상태가 된다. 이렇게 Statging Area에 등록된 모든 파일들은 추후 커밋으로 생성된 스냅샷에 포함된다.
- Staging Area에 있는 파일들을 커밋해서 Git 디렉토리에 영구적인 스냅샷으로 저장한다.

Git 디렉토리에 있는 파일들은 Committed 상태이다. 파일을 수정하고 Staging Area에 추가했다면 Staged이다. 그리고 Checkout 하고 나서 수정했지만, 아직 Staging Area에 추가하지 않았으면 Modified이다.
위 핵심 내용들은 사실 Git을 사용해보지 않았으면 받아들이기 모호하기도 하고, 바로 이해하기 어려울 수 있다. 지금부터는 프로그래밍 관점에서 Git의 원리에 조금 더 다가가 보겠다.
💡 간단한 명령어들은 따로 설명하지 않기 때문에, 기초 명령어들을 알고 싶다면 Github Cheat Sheet를 참고하자. 또한 Git은 에러 메세지나 도움말 명령어가 매우 잘 되어있다. 이를 적극 활용하길 추천한다.
Git의 데이터 모델
Git은 간단해 보이지만 매우 정교한 데이터 모델을 가지고 있다. Git에서는 파일을 blob 이라고 하며, 바이트 묶음으로 이루어져 있다. 디렉토리는 tree 라고 하며, 이름을 blob 또는 tree 에 매핑한다.
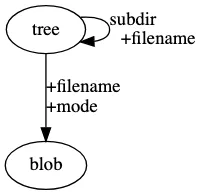
그리고 최상위 디렉토리 내의 폴더와 파일 목록에 대한 기록을 일련의 스냅샷으로 모델링 하는데, 이 스냅샷을 생성한 결과가 commit 이다. Git에서는 blob, tree, commit 을 모두 객체로 생성하고 관리한다.
아래는 의사 코드로 작성된 Git의 데이터 모델이다.
// 파일
type blob = array<byte>
// 트리
type tree = map<string, tree | blob>
// 커밋
type commit = struct {
parent: array<commit>
author: string
message: string
snapshot: tree
}
type object = blob | tree | commitcommit 객체를 보면 구조체 안에 snapshot: tree 가 있는데, 이는 스냅샷을 tree 객체로 저장한다는 것이다. 사실 스냅샷은 커밋 이전에 Staging Area에 올라가 있던(추적 중인) 최상위 트리(디렉토리)다. 그리고 이 스냅샷에 이전 커밋 정보(부모 커밋), 커밋 메세지, 작성자에 대한 부가 정보를 추가한 데이터 객체가 commit이다.
- 최상위 Staged 트리(디렉토리) == 스냅샷
- 스냅샷 + 이전 커밋(부모) + 커밋 메세지 + 작성자 == 커밋
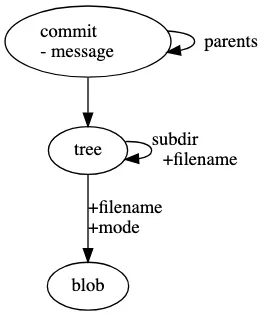
어떻게 최상위 트리 하나가 전체 스냅샷이 될 수 있을까? 이는 Git의 핵심 요약 첫 번째에서 언급했듯이 파일들의 변경사항이 아닌 스냅샷을 링크 형태로 관리하기 때문이다. 최상위 트리에는 하위 tree(디렉토리) 및 blob(파일)들의 정보를 담고 있는 링크 주소같은게 있다. 이 링크들을 따라가다 보면 커밋 당시의 프로젝트 상태를 모두 확인할 수 있다. 그리고 최상위 트리 역시 링크 주소가 있고, 커밋은 이 링크 주소를 값으로 가지고 있는 것이다. 심지어 커밋 조차 링크 주소를 가지고 있다. 이 링크 주소가 바로 sha-1 해시로 만든 40자 길이의 16진수 문자열이다. 직접 실습해 보며 눈으로 확인해 보면 이해가 될 것이다.
객체들의 주소화 → sha-1 hashing
먼저 커밋 로그를 확인해 보자.

commit 옆에 16진수 문자열이 길게 표기된 걸 확인할 수 있는데, 이 문자열이 바로 commit 객체 내용을 sha-1으로 해시한 체크섬 값이다.
objects = map<string, object>
// 객체 저장 함수
def store(object):
id = sha1(object)
objects[id] = object
// 객체 로드 함수
def load(id):
return objects[id]위 의사코드를 보면, objects 안에는 blob, tree, 및 commit 객체들을 담고 있는 map인데, key가 체크섬 string이고 value가 실제 객체(주소)다. git 명령어를 사용해 이 체크섬으로 실제 객체들에 담긴 정보를 시각화 할 수도 있다.

내용을 보면 tree에 대한 체크섬도 확인할 수 있다. 이것도 한 번 조회해 보자.

가장 먼저 보이는 6개의 숫자는 파일 모드다.
- 100644: 일반 파일(읽기/쓰기 가능).
- 100755: 실행 파일(실행 권한 부여).
- 040000: 디렉터리.
그 다음으로 2개의 객체 타입이 온다.
- blob: 파일의 내용을 저장하는 Git 객체
- tree: 디렉터리의 내용을 저장하는 Git 객체
그 다음 보이는 16진수는 당연히 체크섬이고, 다음으로 파일(blob)이나 디렉토리(tree)의 이름이 표시된다.
이제 마지막으로 blob의 체크섬도 열어보자.

마치 쉘의 cat 명령어로 파일의 내용을 출력하는 것과 같은 결과를 확인할 수 있다. 이 과정을 통해서 어떻게 커밋 객체가 트리의 링크 주소만을 가지고 스냅샷을 저장할 수 있는지 감이 잡혔을 것이다.
- commit 링크 주소(체크섬) → tree(디렉토리) 링크 주소 → 하위 tree 링크 주소 or blob(파일) 링크 주소
이러한 방식 때문에 최근 커밋에서 항상 최신의 파일 상태를 확인할 수 있을 뿐만 아니라, 변경되지 않은 파일들을 또 다시 저장할 필요가 없어진다. 단지 트리들이 계층적으로 링크 주소만을 가지고 있으면 된다.
그럼 이 링크 주소는 어디에 생성될까? 궁금한 모든건 Git 디렉토리 안에 있다.
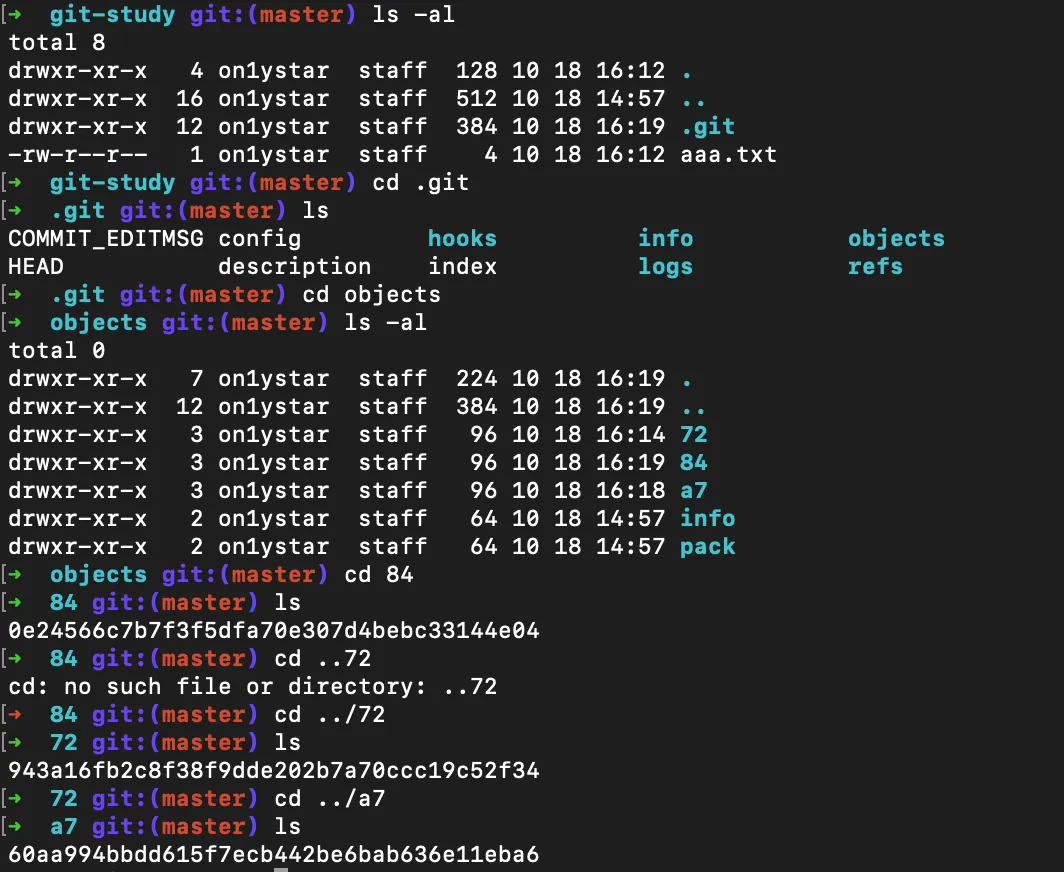
.git/objects 경로 안에 우리가 지금까지 조회해 봤던 링크 주소(체크섬)들이 생성돼 있다. 이 안의 내용들은 해시화 되어 있어 읽을 수 없고, 아까처럼 git 명령어를 통해서만 읽을 수 있다. 때문에 앞서 Git 핵심 요약에서 설명했던 무결성을 보장할 수 있는 것이다.
위 내용들을 토대로 다음 예시를 이해하는데 어려움이 없을 것이다.
- b-directory 디렉토리 생성
- b-directory 디렉토리 안에 bbb.txt 파일 생성
- add → commit
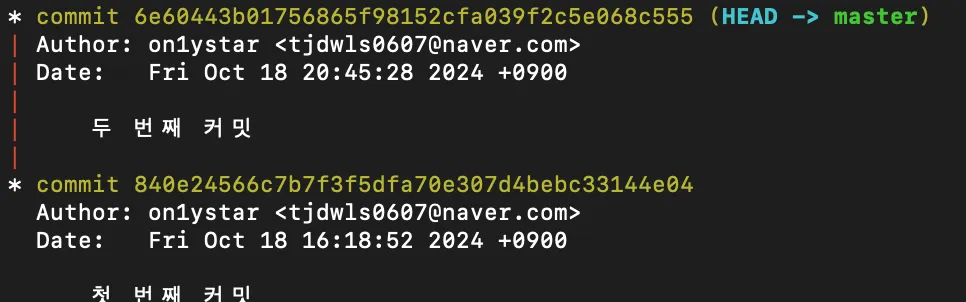
- 두 번째 커밋 체크섬 값을 조회

- 트리(스냅샷) 체크섬 값을 조회

위 결과들이 어떻게 나왔는지 고민해 보길 바란다.
객체들의 이름 References
이제 모든 스냅 샷은 SHA-1 해시로 식별 할 수 있다. 하지만 사람에게 40개의 16진수 문자열은 너무 어렵다. Git은 이 문제를 해결하기 위해 SHA-1 해시에 references 라는 사람이 읽을 수 있는 이름을 사용한다. 우리가 평소에 branch 이름으로 사용하는 master나, 현재 위치(커밋)를 나타내는 HEAD도 다 Git의 초기 설정에 의해 references 로 등록되어 있다.
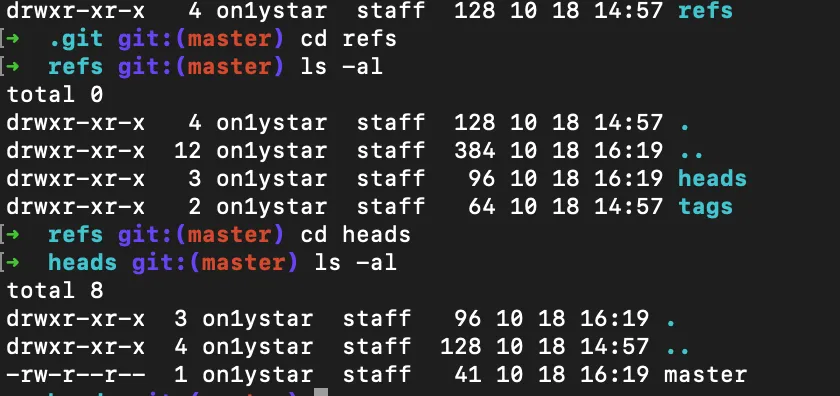
💡 참고로 HEAD 는 commit을 되돌리는 reset 명령어를 수행하거나, 현재 branch를 가리키는 등의 중요한 역할을 한다.
이 refs는 커밋이나 포스트 잇을 붙여 놓는 것과 같은 역할을 한다. 프로그래밍 관점에서 얘기하자면, references는 커밋을 가리키는 포인터 역할을 한다. git init 명령어를 통해 처음 생성된 master branch 역시 우리가 생성할 커밋들을 가리키기 위해 생성된 것이다. 또한 우리가 Github를 사용할 때처럼 원격 저장소를 연결하게 되면 remote refs도 생성된다.
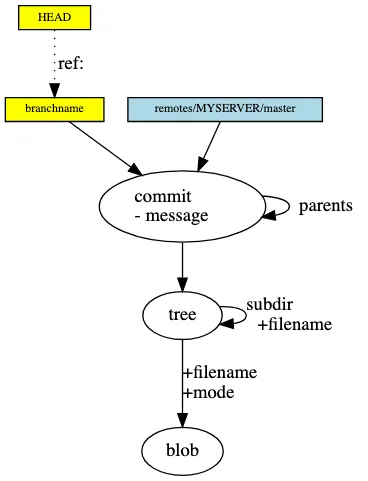
이처럼 Git 저장소는 blob, tree, commit objects와 refs의 모임이며, 해시화된 링크 주소가 디렉토리형태로 저장및 조회되는 것을 어렴풋이나마 이해할 수 있을 것이다.
References
'Git 공부' 카테고리의 다른 글
| Git의 원리를 이해하고 사용하기 - 3 (브랜치, 병합, 리모트 브랜치) (7) | 2024.11.01 |
|---|---|
| Git의 원리를 이해하고 사용하기 - 2 (파일의 라이프 사이클, 되돌리기) (2) | 2024.10.24 |
| Git Github 사용법 (0) | 2019.03.18 |
| Git fatal: refusing to merge unrelated histories (0) | 2019.03.15 |
| Git 병합 충돌 (0) | 2019.03.11 |
- Total
- Today
- Yesterday
- 파이썬 for Beginner 연습문제
- Thymeleaf
- Do it! 정직하게 코딩하며 배우는 딥러닝 입문
- 파이썬 for Beginner 솔루션
- Computer_Networking_A_Top-Down_Approach
- 김영환
- jsp
- Python Cookbook
- 패킷 스위칭
- 스프링 컨테이너
- 스프링 테스트
- git
- 스프링
- 생활코딩 javascript
- Spring
- 지옥에서 온 git
- 프로그래머스
- Spring Data JPA
- fetch join
- Spring Boot
- 쉘 코드
- git branch
- 방명록 프로젝트
- 운영체제 반효경
- 쉽게 배우는 운영체제
- git merge
- JPA
- Gradle
- 스프링 mvc
- 선형 회귀
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |